
908PS-2 - MODELLI LINEARI APPLICATI 2025
Section outline
-
Chiarimenti sulla modalità d'esame.
L'esame è composto da due fasi distinte:
- Fase di lavoro "domestico": Per poter accedere all'esame con una base di partenza minima di 18/30 è necessario creare una propria cartella "Compiti_COGNOME" sul canale Teams del corso, dove caricare tutti gli esercizi assegnati durante le lezioni. Lo svolgimento di tutti i compiti assegnati è un prerequisito necessario per poter accedere all'esame vero e proprio "in presenza". In aggiunta, prima della partecipazione alla fase 2, sarà necessario caricare anche un Glossario preparato con cura e autonomamente, contenente tutti i termini tecnici nuovi presentati a lezione. Il Glossario potrà contenere spiegazioni basate sul materiale presentato a lezione, su ricerche autonome e naturalmente sul libro di riferimento del corso (Categorica Data Analysis, Agresti). Il docente controllerà il materiale caricato (...attenzione all'uso dell IA) e darà eventualmente il parere favorevole alla partecipazione all'esame scritto. A tal riguardo, il materiale dovrà essere presente nella propria cartella una settimana prima della data dell'esame scritto.
- Esame scritto "in presenza": nelle date ufficiali, si svolgerà un'esame scritto per completare la valutazione finale (voto finale max. 30/30). L'esame sarà costituito da (a) 6 esercizi da svolgere con il programma statistico R e (b) 6 quesiti aperti e problemi da svolgere su carta, consentendo il raggiungimento di (max) 12 punti da sommare ai 18 conseguiti precedentemente. Sarà necessario portare il proprio pc/tablet + un formulario preparato autonomamente (A4 fronte-retro) con tutte le formule (solo quelle, con minimi commenti) ritenute utili. L'esame durerà due ore: nella prima ora si svolgerà la prova in R, alla fine della quale gli script R prodotti verranno inviati (immediatamente) via email al docente. A partire dalla seconda ora, si potrà iniziare la prova scritta vera e propria solo con l'ausilio del formulario (i pc/tablet verranno chiusi e messi via). Terminate le due ore, l'esame scritto verrà consegnato al docente. Nel caso non venisse svolto alcun esercizio, la valutazione conseguita sarà solamente quella minima (18/30), garantita dalle attività del punto 1.
-
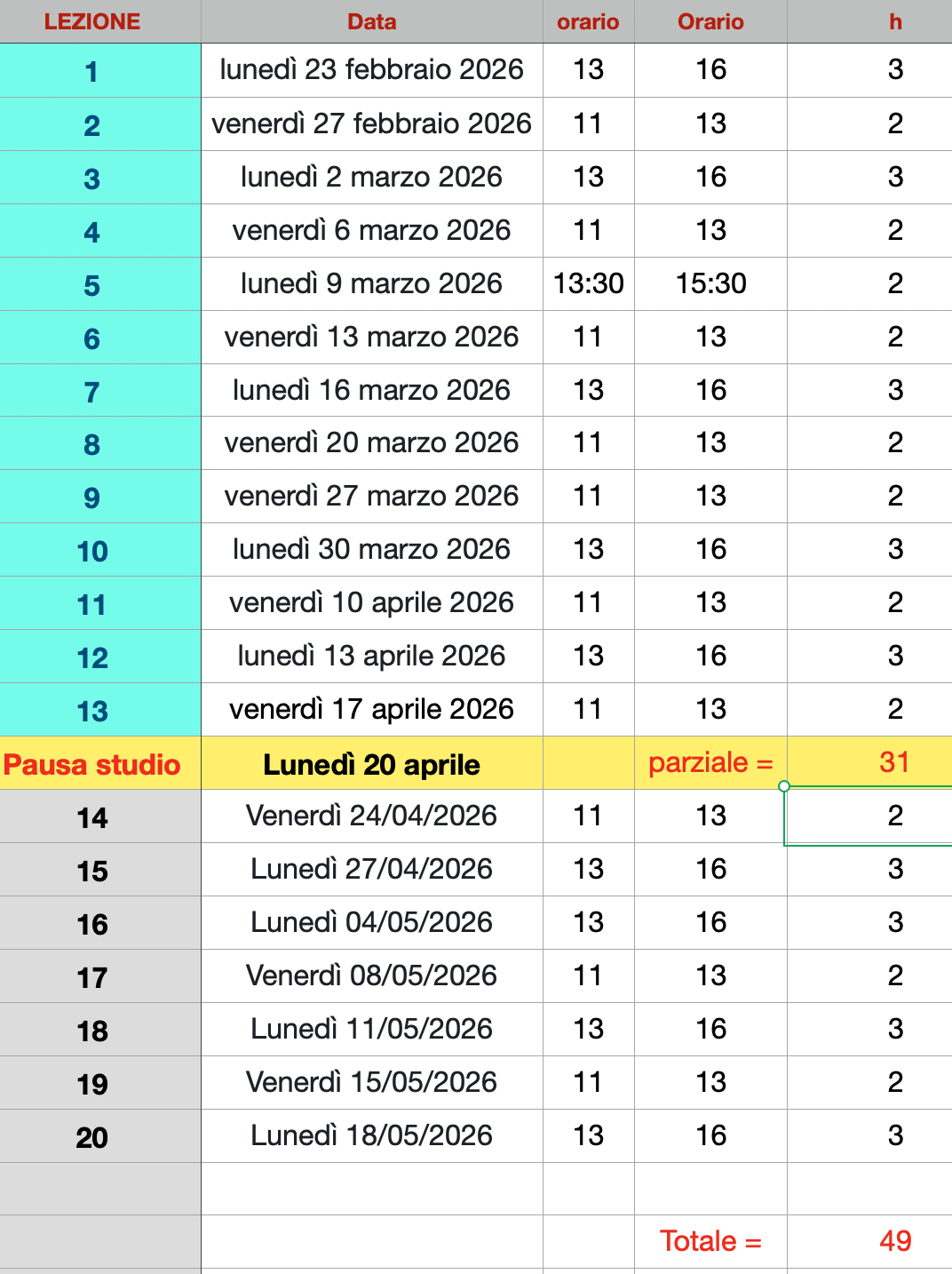
Lunedì 23 febbraio 2026
13:00 - 16:00
Breve presentazione del corso
Chiarimenti sulla modalità di svolgimemento dell'esame finale
Breve ripasso sul modello lineare bivariato e multiplo (si consiglia un ripasso individuale sui testi usati durante la triennale)
Il concetto di derivata e sua applicazione nell'individuazione del minimo di una funzione (Formula della varianza campionaria con centro generico "c", vedi lezioni su Teams)
Esempio generico di "ottimizzazione" mediante diseguaglianza "Media Aritmetica - Media Geometrica" (vedi lezioni registrate su Teams)
Canale Teams ufficiale del Corso:
Generale | CD2025 908PS-2 MODELLI LINEARI APPLICATI | Microsoft Teams
COMPITO:
Produrre degli appunti della lezione (PC o a mano, è uguale) e caricarli sulla cartella condivisa della pagina Teams del corso.
salvare il file "Cognome_Compiti_1" (.pdf o Word, se foto allora consolidare su unico file .pdf magari incollando prima le foto su PowerPoint, salvando come .pdf)
-
Lezione 1 MLA File XLSX
-
-
venerdì 27 febbraio 2026
11:00 - 13:00
Il modello di regressione lineare bivariato e multiplo: rappresentazione grafica e matrice del modello di 7 casi generali.
Canale Teams ufficiale del Corso:
Generale | CD2025 908PS-2 MODELLI LINEARI APPLICATI | Microsoft Teams
-
Lunedì 2 marzo 2026
13:00 - 16:00
Stima di massima verosimiglianza (MLE) dei parametri della funzione di densità di probabilità Normale.
Convergenza delle stime MLE con media e varianza campionaria.
Le derivate seconde parziali e cross-parziali: legame con la varianza/covarianza dei parametri MLE
COMPITO:
Vedi diapositive della lezione
-
venerdì 6 marzo 2026
11:00 - 13:00
Stima di massima verosimiglianza (MLE) di "p" in una serie di Bernoulli (analisi di dati dicotomici 0-1).
Relazione tra derivata seconda della funzione Log-likelihood e precisione delle stime MLE.
-
Lunedì 9 marzo 2026
13:30 - 15:30
Linguaggio di programmazione R: Grafici e funzioni di base.
Analisi dell'articolo e replica della procedura iterativa proposta mediante programmazione in R
Camilli, G. (1994). Teacher’s Corner: Origin of the Scaling Constant d = 1.7 in Item Response Theory. Journal of Educational and Behavioral Statistics, 19(3), 293-295.
____________________
SURVEY PROGETTO
PRO-BENE-COMUNE
Università di TriesteQR Code

oppure Link: https://dsvunits.qualtrics.com/jfe/form/SV_3JVFIafYxOgCUwC
RESPONSABILE SCIENTIFICO UNITS: PROF.SSA BARBARA PENOLAZZI
Referente per il Benessere Psicologico
Note. a) Rivolto a chi non ha mai compilato in precedenza la survey del progetto, sia a chi l’ha fatto l’anno scorso (per avere dati longitudinali); b) nel rispetto delle norme sulla privacy i dati saranno pseudonimizzati (non sarà possibile risalire ai nominativi originali)

-
Venerdì 13 marzo 2026
11:00 - 13:00
Linguaggio di programmazione R: funzione repeat.
Analisi dell'articolo (conclusione e replica della procedura iterativa)
Camilli, G. (1994). Teacher’s Corner: Origin of the Scaling Constant d = 1.7 in Item Response Theory. Journal of Educational and Behavioral Statistics, 19(3), 293-295.
-
Lunedì 16 marzo 26
13:00 - 16:00
Operazioni con vettori e matrici in R
Somma/differenza, prodotto interno/esterno tra vettori;
Somma/differenza, e prodotto tra matrici (e vettori) conformabili.
Matrice trasposta, matrice (quadrata) inversa e determinante di una matrice (quadrata).
Esempio applicativo in R: calcolo dei coefficienti di regressione lineare mediante operazione matriciale.
COMPITI: vedi file .pdf allegato
-
Venerdì 20 marzo 2026
11:00 - 13:00
∗ Alcuni metodi iterativi per il calcolo della stima di verosimiglianza (Newton-Raphson, metodo dello scoring di Fisher).
∗ Applicazione sulla stime MLE per la distribuzione binomiale (p) e normale (μ e σ).
-
Venerdì 27 marzo 2026
11:00 - 13:00
∗ Programmazione in R dei metodi iterativi 'Newton-Raphson' e 'scoring di Fisher' per il calcolo della stima di verosimiglianza di 'p' (binomie) e μ e σ (normale).
Compiti: consegnare lo script in R svolto durante la lezione (normale) + quello relativo alla binomiale (da svolgere in autonomia)
-
lunedì 30 marzo 2026
13:00 - 16:00
Stima di massima verosimiglianza del modello lineare con errore normale.
COMPITI: a pg. 10 delle diapositive ci sono due esercizi di ripasso sul materiale presentato a lezione.
-
Venerdì 10 aprile 2026
11:00 - 13:00
Il modello di regressione lineare: Stima iterativa con metodo di Fisher scoring – Applicazione in R.
Ritrovare i risultati della funzione glm() all'interno della procedura iterativa di massima verosimiglianza.
-
Lunedì 13 aprile 2026
13:00 - 16:00
Il modello lineare di probabilità ed il modello Logit: introduzione ed interpretazione dei parametri del modello.
Il modello Logit: stima di massima verosimiglianza (iterativa) dei parametri del modello.
-
venerdì 17 aprile 2026
Il modello Logit: stima di massima verosimiglianza (iterativa) dei parametri del modello.
Residui nel modello GLM Logit e concetto di osservazione outlier: Deviance residuals, Raw and Pearson residuals.
Applicazione in linguaggio R
COMPITO:
Vedi all'interno delle diapositive della lezione.
-
venerdì 24 aprile 11-13
"Sparse Data" e problemi di convergenza del modello: Discussione di tre casi (variabile x dicotomica, variabile x continua e due variabili x continue)
Inferenza sui parametri del modello di regressione logistica.
(a) Wald test; (b) Combinazioni lineari di coefficienti (metodo Delta + approfondimento); (c) Intervallo di fiducia per il Logit e la probabilità stimata; e (d) test Chi quadrato (LRT) per il confronto tra modello "nullo" ed "alternativo" (+ Approfondimento sul concetto di "Deviance")
Nota: La registrazione su Teams da un certo punto in poi non ha l'audio. A breve ne caricherò una "nuova".
-
lunedì 27 aprile 13:00. - 16:00
(Continua...) Inferenza sui parametri del modello di regressione logistica.
(a) Wald test; (b) Combinazioni lineari di coefficienti (metodo Delta + approfondimento); (c) Intervallo di fiducia per il Logit e la probabilità stimata; e (d) test Chi quadrato (LRT) per il confronto tra modello "nullo" ed "alternativo" (+ Approfondimento sul concetto di "Deviance")
-
lunedì 4 maggio 13:00 - 16:00
Simulazione con R:
- Distribuzione Chi-quadrato
- Distribuzione della differenza tra due variabili casuali indipendenti Chi-quadrato- Approssimazione normale
- Distribuzione della differenza tra due variabili casuali non indipendenti (nested) Chi-quadrato
- Distribuzione della differenza tra la (Residual) Deviance di un modello ridotto (nested) e un modello completo di regressione logistica - Approssimazione alla distribuzione Chi-quadrato con gradi di libertà pari al numero di predittori (coefficienti) rimossi nel modello ridotto.
Compiti per casa:
a) Utilizzando il "dataset08.RData" (oppure copia-incolla il file dataset08TABLET.txt, nel caso non fosse possibile caricare data set esterni su tablet) calcolare con R i Wald tests per tutti i coefficienti del modello "MHSUITHK ~ IRSEX + NDSSDNSP + DEPNDALC + DEPNDCOC + DEPNDHER + DEPNDANL + DEPNDSED + DEPNDSTM + DEPNDHAL + DEPNDINH + DEPNDMRJ + DEPNDTRN"
b) Confrontare mediante test LRT il modello precedente (completo) con un modello ridotto (nested) contenente solo i predittori IRSEX + DEPNDALC. Esplicitare ipotesi nulla e alternativa, commentare il p-valore ottenuto.
c.1) Mediante il metodo Delta, confrontare la differenza tra gli effetti stimati per cocaina ed eroina.
c.2) Confrontare la differenza tra l'effetto medio di cocaina ed eroina con l'effetto stimato per la marijuana. (Suggerimento: per creare effetti "medi" usare dei pesi nel vettore v pari a 1/k, dove k è il numero di coefficienti da mediare).
d.1) Calcolare l'intervallo di fiducia al 95% per la probabilità prevista di tentato suicidio nel caso di: "maschio", dipendente da abuso di alcool e cocaina.
d.2) Calcolare il medesimo intervallo di fiducia nel caso di una "femmina".
-
venerdì 08 maggio 11-13
Introduzione alla teoria della detenzione del segnale (SDT):
- L'esperimento "YES"/"NO", concetto di sensitività e bias di risposta
- Le tabelle stimolo-risposta, classificazione delle risposte "YES" (Hit, False-alarm) e "No" (Miss, Correct rejections)
- il d' (d prime) come misura di sensitività, esempi di calcolo in Excel
Compiti: 1.1-1.2-1.3-1.4 all'interno del .pdf
-
Lezione 17 MLA File XLSX
-
lunedì 11 maggio 13-16
Introduzione alla teoria della detenzione del segnale (SDT):
- Lo spazio ROC e le curve di isosensitività (coppie (Hit; False-Alarm) con d' costante)
- Lo spazio ROC in coordinate trasformate (punti z): interpretazione geometrica dell'indice di sensitività d'.
- Esempi di calcolo in Excel
Compiti: 1.6-1.8-1.9-1.11 all'interno del .pdf
-
Lezione 18 MLA File XLSX
-
venerdì 15 maggio 11-13
CURVE ROC:
Concetto di AUC e applicazione nel modello Logit.
-
lunedì 18 maggio 14-16
CURVE ROC e modello Logit:
applicazione in R con il pacchetto "pROC"
Compiti per casa
Con il "dataset08.RData" stimare un modello contenente solo i predittori "IRSEX + DEPNDALC" ed uno contenente tutti i predittori tranne "IRSEX + DEPNDALC". Interpretare i coefficienti stimati di entrambi i modelli (scrivere brevemente l'effetto).
Confrontare la capacità di discriminazione dei modelli precedenti mediante l'indice AUC, calcolarne il d' associato ed interpretarlo. Disegnare le curve ROC dei due modelli.
Eseguire un test di DeLong per i due modelli precedenti ed interpretarlo.
Utilizzando il dataset "hcrabs" della libreria "rsq", identificare un numero ristretto ("parsimonioso") di predittori che abbia la stessa accuratezza classificatoria del modello completo, contenente tutti i predittori "color+spine+width+weight". Scrivete brevemente il processo analitico (corredato di grafici e test statistici inclusi) che vi ha condotto al modello finale.